David,
Thanks for sharing! For anyone interested in how you can use LLMs to help build simulations and test different things quickly, this is a fantastic example.
Besides the obligatory WarGames movie reference, "Shall we play a game?" that immediately came to mind, just in the few minutes that I played around with this simulation, it's not only a great way to test the utility of current AI models as agents/decision-makers, but simulations like this can more easily implement tests of policies (human versions of 'prompts') that you might give an employee. And the fact that GPT-5-mini does better shows that the AI researchers are still making progress on reasoning and problem-solving capability, though running it on gpt-5-mini does take significantly longer in your simulation app (gpt-4o-mini: ~15 sec; gpt-41-mini: ~20 sec; gpt-5-mini: ~5 min).
Even running a single instance with each of the three OpenAI mini models (this sim has info sharing & downstream inventory visibility 'on') gives us questions to think about, one of which is what should be our trade-off between time/cost of the decision vs the improvement? In these runs, I saw improvement from gpt-4o-mini to gpt-41-mini, but not as much from gpt-41-mini to gpt-5-mini.
gpt-4o-mini:
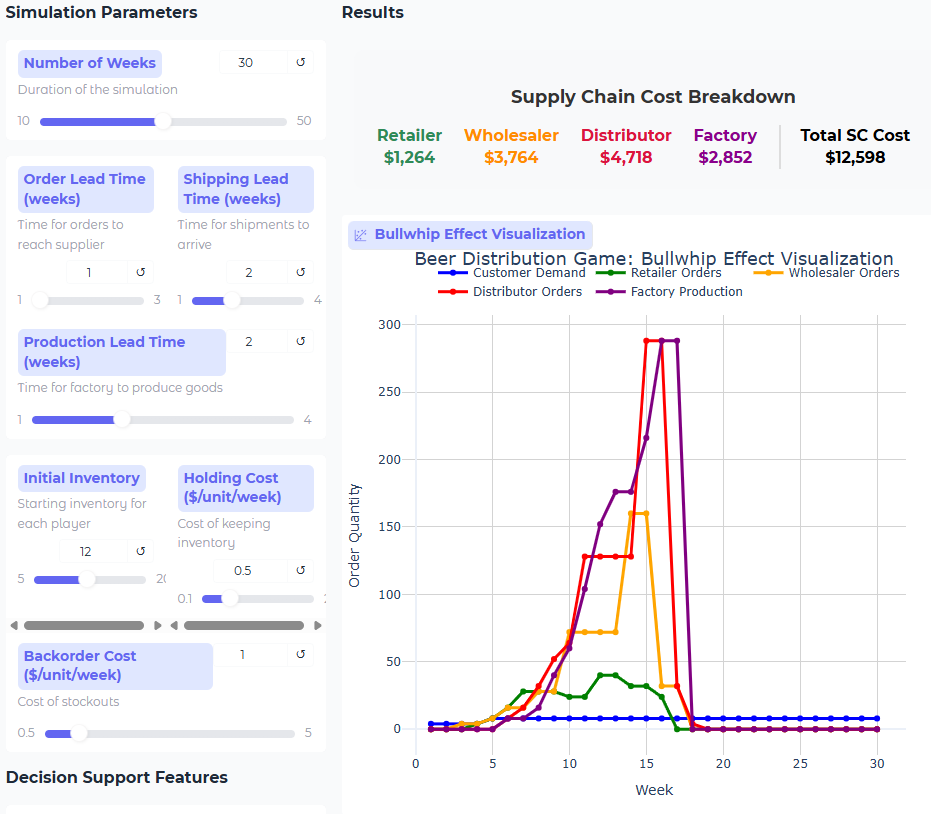
gpt-41-mini:
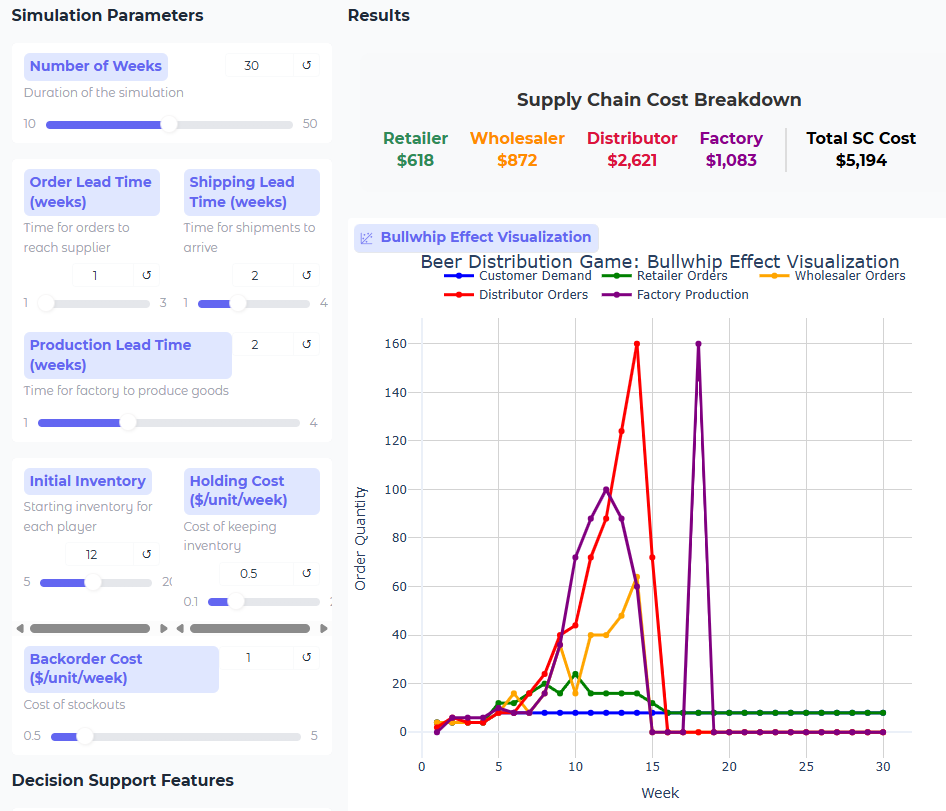
gpt-5-mini:
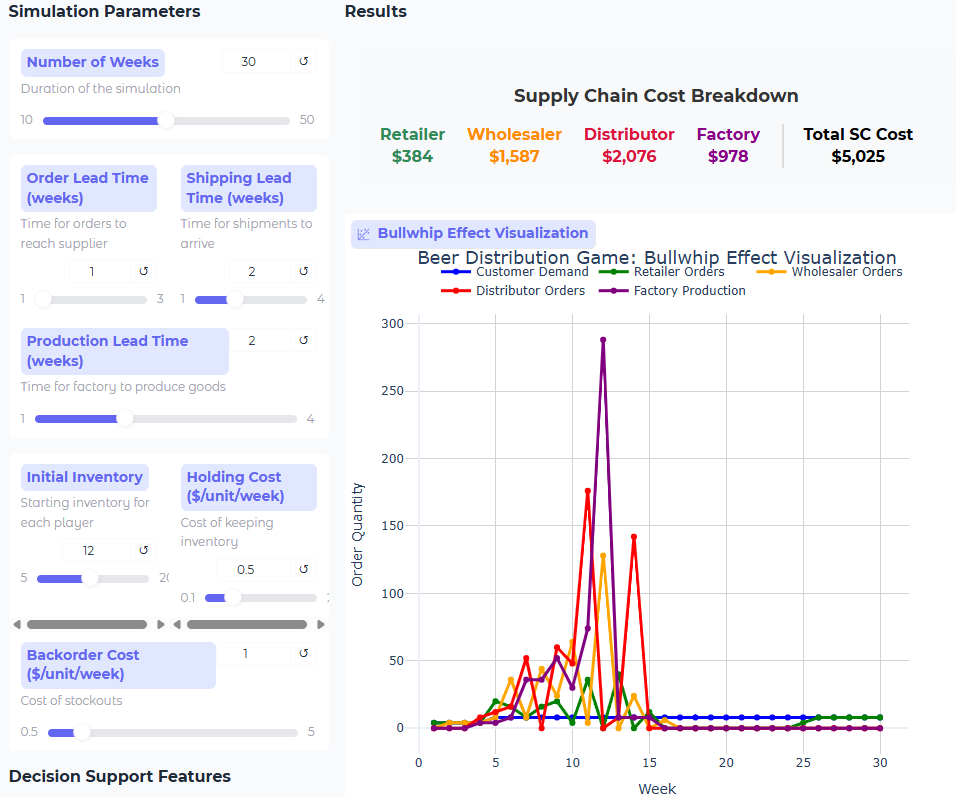
------------------------------
Warren Hearnes, PhD
Founder, OptiML AI
INFORMS Board Role: VP Technology Strategy
------------------------------
Original Message:
Sent: 08-29-2025 10:59
From: David Simchi-Levi
Subject: Can GenAI agents 🤖 manage a supply chain? Lessons from the classical Beer Game.
Hi everyone,
A joint team from #Harvard Information Theory Lab, #MIT Data Science Lab, and #GeorgiaTech Business School has built the first live simulation of the Beer Game powered by LLMs 🎯
Experts suggest that fully autonomous supply chains-where AI makes all the supply chain (e.g., inventory) decisions-may be just around the corner. But how close are we really? To explore this, we reimagined the classical Beer Game: every facility is now run entirely by a GenAI agent.
🔹 In decentralized mode, each agent makes independent ordering decisions.
🔹 In centralized setups, a supply chain orchestrator provides the different agents with varying levels of information sharing. Decisions are still made only by the individual agents.
🔹 Performance is evaluated through the total supply chain cost and the bullwhip effect, which are key indicators of supply chain efficiency.
The simulation supports multiple state-of-the-art Large Language Models (#GPT, #Llama, #DeepSeek, #Phi) and offers tunable parameters, letting you experiment with diverse supply chain scenarios.
👉 Try the interactive simulation here: https://infotheorylab.github.io/beer-game/
At the end of the page, you will find "Lessons Learnt from the GenAI Beer Game" but of course, you are welcome to draw your own conclusions.
Best
David
------------------------------
David Simchi-Levi
Professor of Engineering Systems
MIT
Cambridge MA
------------------------------